
Last month at the AWSUKUG meetup I talked about Video Factory, and there was a little section there where I spoke aboutthe tooling that we use to manage all of our components. One of the tools, “stack-fetcher”, generated quite a bit of interest from the audience, and there was interest in open-sourcing it. I definitely want to do this — but we're not quite there yet.
For now, though, I can talk about where stack-fetcher is right now, and what direction I want to take it in.
The problem space
“AWS CloudFormation gives developers and systems administrators an easy way to create and manage a collection of related AWS resources, provisioning and updating them in an orderly and predictable fashion,” says the documentation. As a developer, you do this by creating a template (JSON which defines one or more desired resources), then submitting that template to CloudFormation — either via the API, or via something which wraps the API (e.g. the web console). Then CloudFormation goes and creates or updates your stack to match your template.
As a developer who loves automation and consistency, this leaves you with several problems:
- How do I generate the template JSON?
- How do I generate the other JSON required by the stack (e.g. parameter values)?
- If I was to push that JSON to CloudFormation — i.e. apply the change — how do I know what changes I'm actually pushing?
- Can I push some changes but not others?
- Once I know what I want to push, how do I do so?
A little BBC Media Services history
To put all of the above into a specific story: in BBC Media Services, we found during the development of Video Factory that we were managing more and more stacks, and by the start of this year we had something like 100 stacks to manage in each of our three environments.
By January 2014, we had a system for generating the JSON, but different people ran the relevant tools in different ways, therefore sometimes yielding differing results. And once the JSON had been generated, we had no way of knowing in what way it was different from the stack's existing template, so we didn't know what we were actually changing. And finally, we had no consistent approach for actually updating the stacks with the new template — mostly we were using the web console, but not always in the same way. And even then: it's a web console, so that's just awful from a productivity and automation point of view.
Thus, stack-fetcher was created, to address all of the above problems.
The workflow
Once you've updated your source files, the workflow to update a stack consists of three steps:
- Run “stack-fetcher”. This generates a set of three files: current, generated, and next.
- Use your favourite diff/merge tool to compare the current, generated and next files, making whatever changes you wish to next.
- Run “stack-updater” to push next into CloudFormation.
The workflow in action
Here's a demo of a simple change, illustrating the basic workflow, and some of stack-fetcher's strengths.
Before running stack-fetcher, We have two stacks, “resource” and “component”. The first diff has already been applied: a queue was added to the resource stack. These screenshots show the second diff being applied: to modify the IAM policy defined in the “component” stack, such that access is granted to the queue in the resource stack.
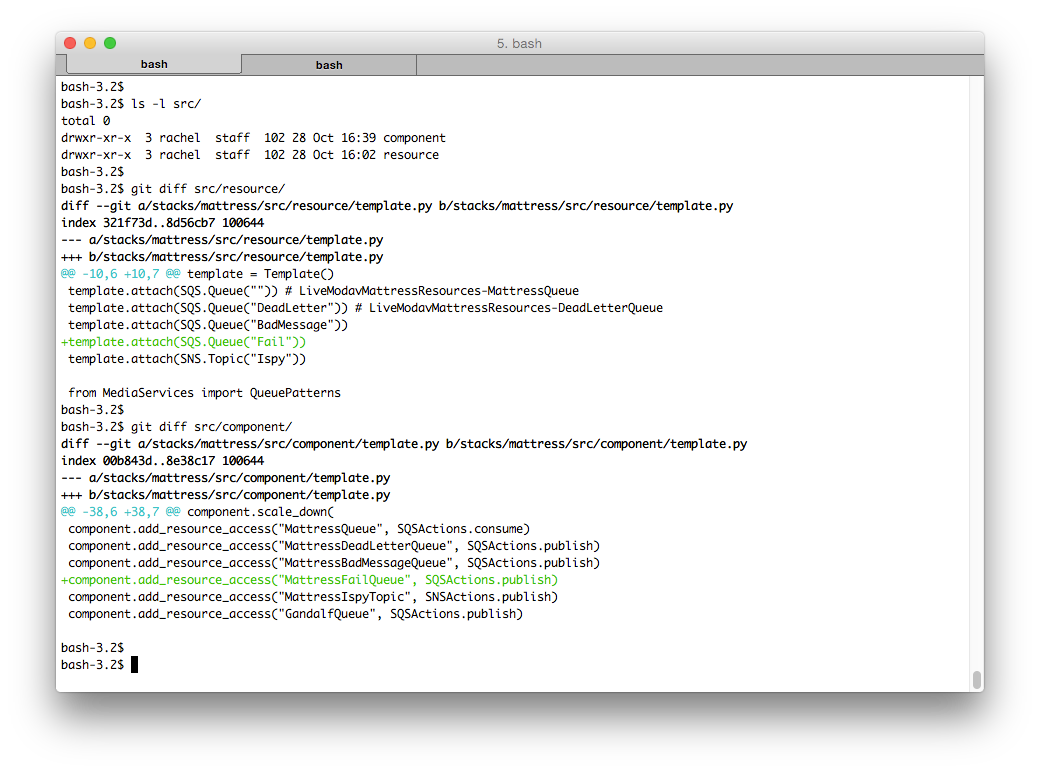
We then run stack-fetcher (in this example, “int” is the environment in question — integration). stack-fetcher retrieves the existing stack, generates the desired template, and compares the two. The summary shows “resource: same” (all in sync), and “component: DIFFERENT (20 lines)” (there are 20 lines of differences).
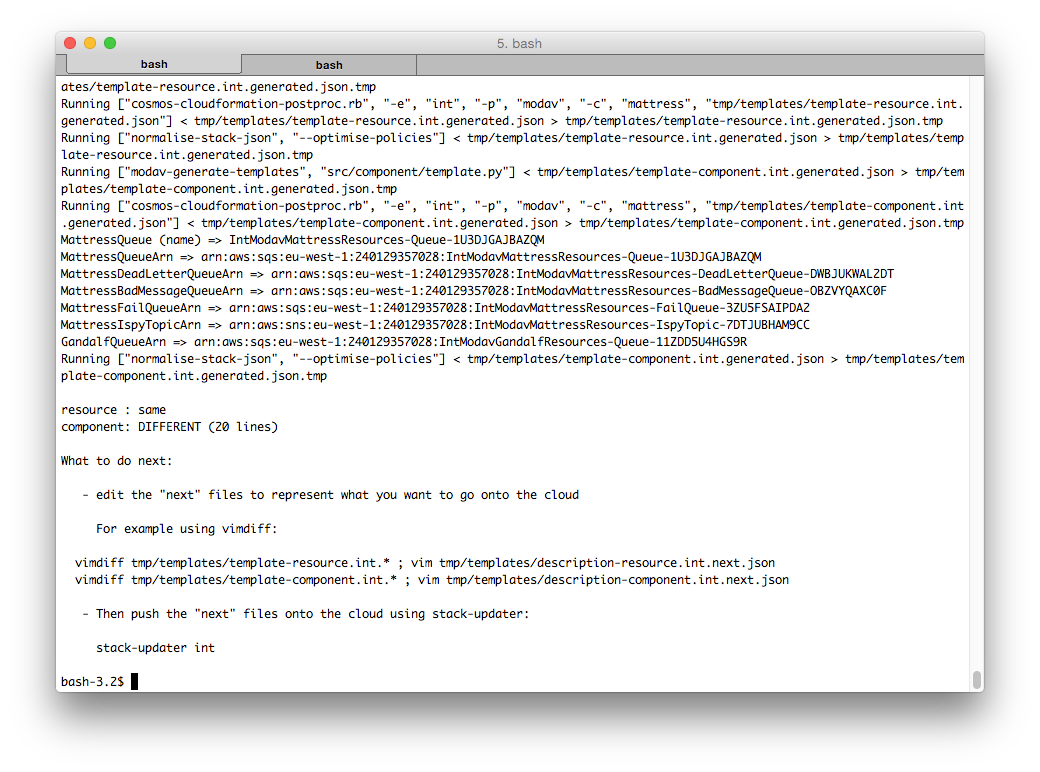
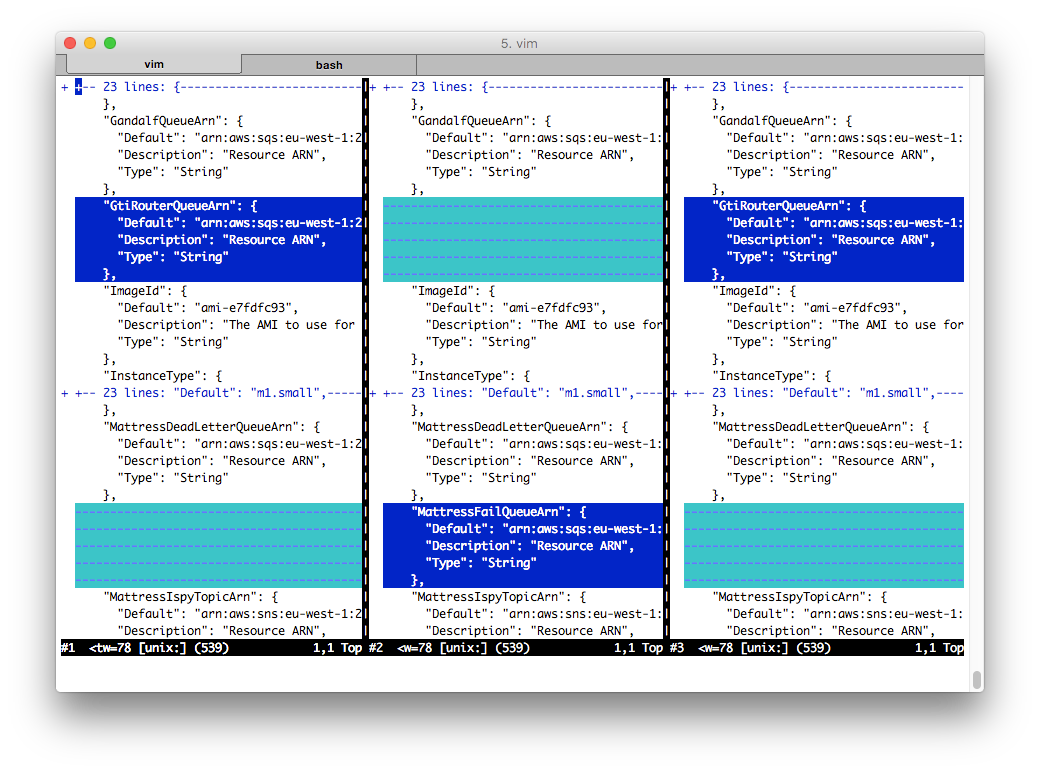
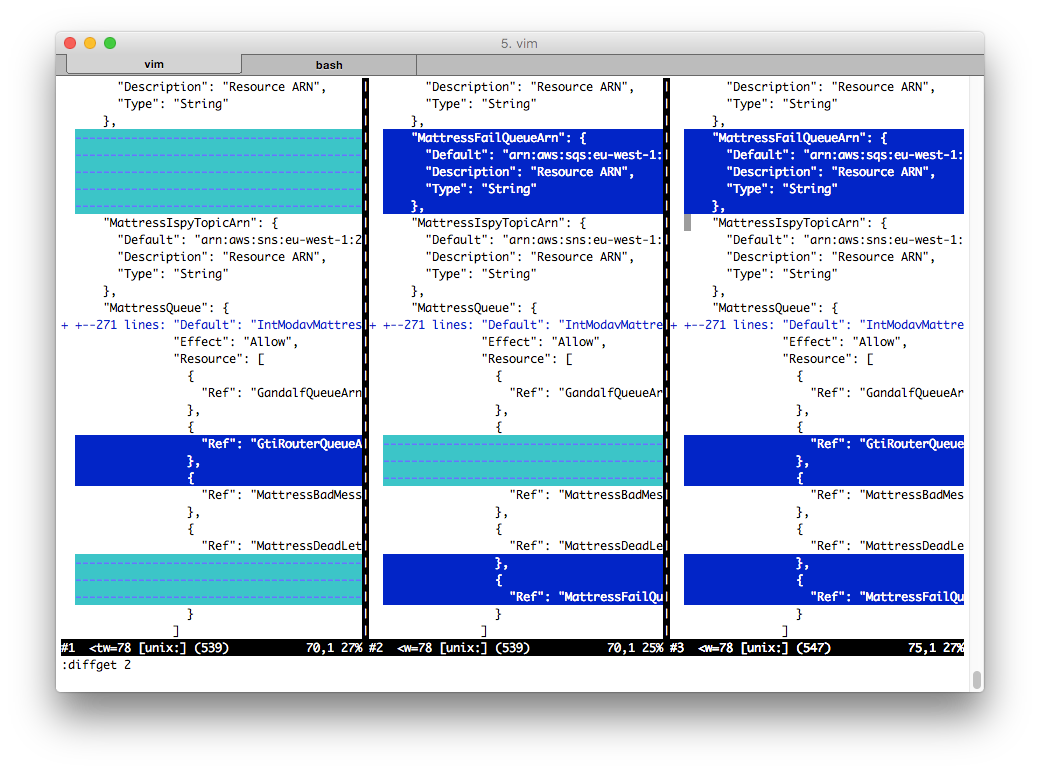
stack-fetcher has generated three template files per stack: current, generated, and next. Here we see the three files compared, using vimdiff:
and the bottom half of the same files:
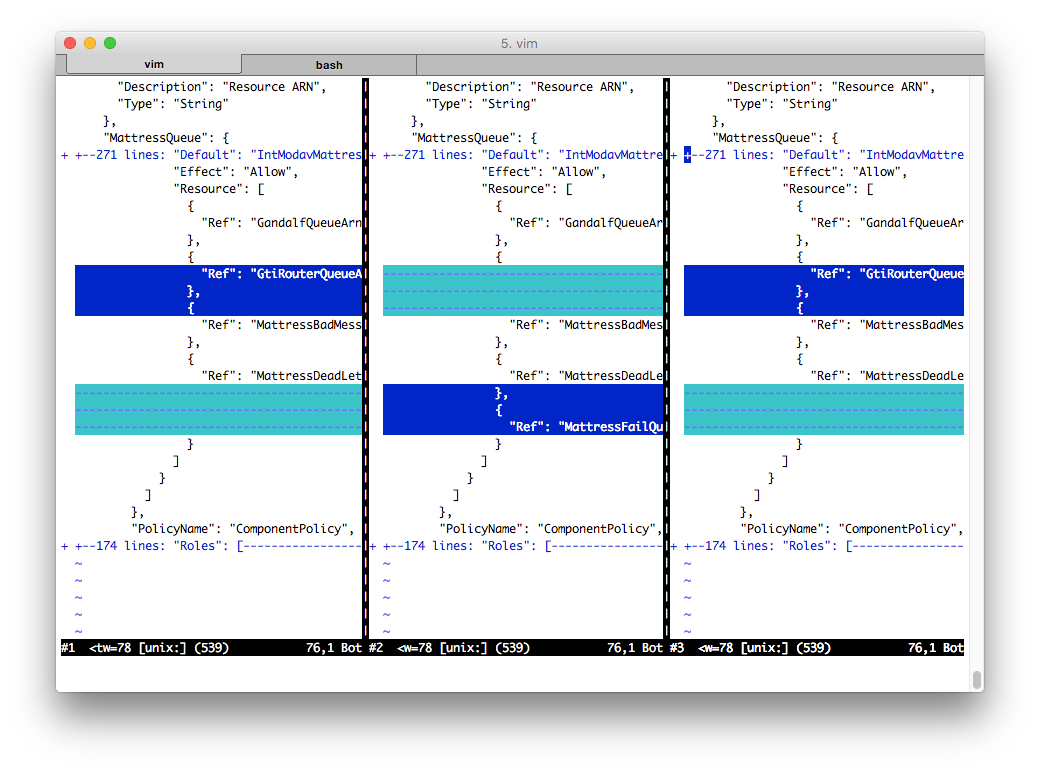
You can see that “generated” (in the middle column) has some sections that “current” doesn't — these is for the policy change we're trying to make. But you can also see that “current” has some lines that “generated” doesn't. This is because in this example, the stack in CloudFormation started off not in sync with our local copy (for example, maybe someone applied a change but neglected to commit the corresponding source).
So now we modify “next” (the right-hand file) to match whatever changes we want to apply. In this example we choose to pull in the new lines, but elect not to remove the extra, unexpected ones:
After saving these changes (remember, we didn't modify “current” or “generated” — only “next”), we run stack-updater:
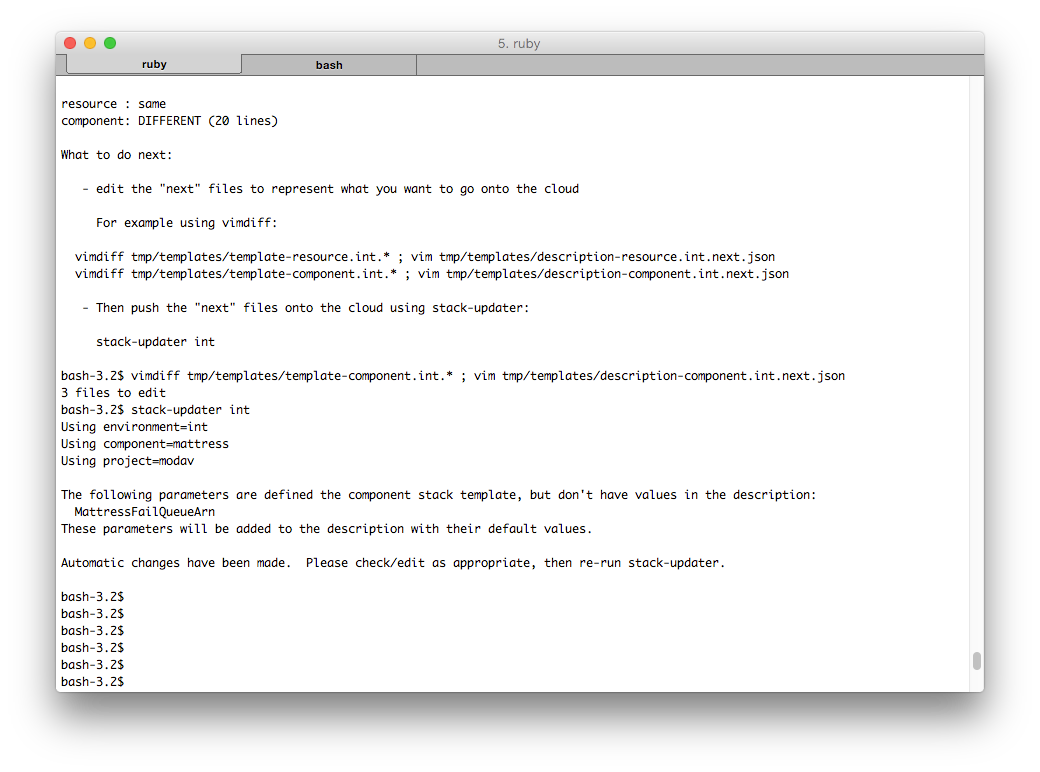
stack-updater now warns us that it has detected a new parameter on the template (“MattressFailQueueArn” in this example): it adds this parameter, with the default value from the template, to the description file; then invites us to check this and edit the description file if we wish.
In this case the default is fine, so we just run stack-updater again:
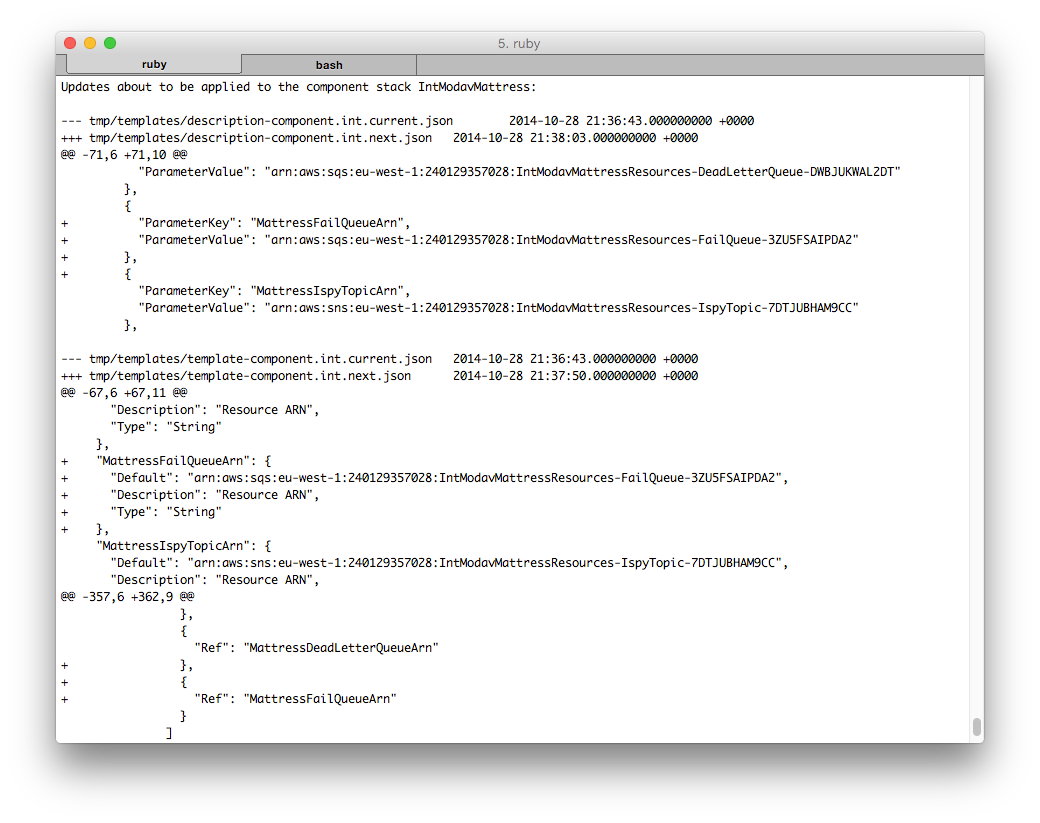
Now stack-updater very clearly shows us the diffs between current and next: that is, if we elect to proceed, these are the changes that we're actually about to make.
After confirming that we're OK with this, stack-updater applies these changes, using the CloudFormation UpdateStack API:
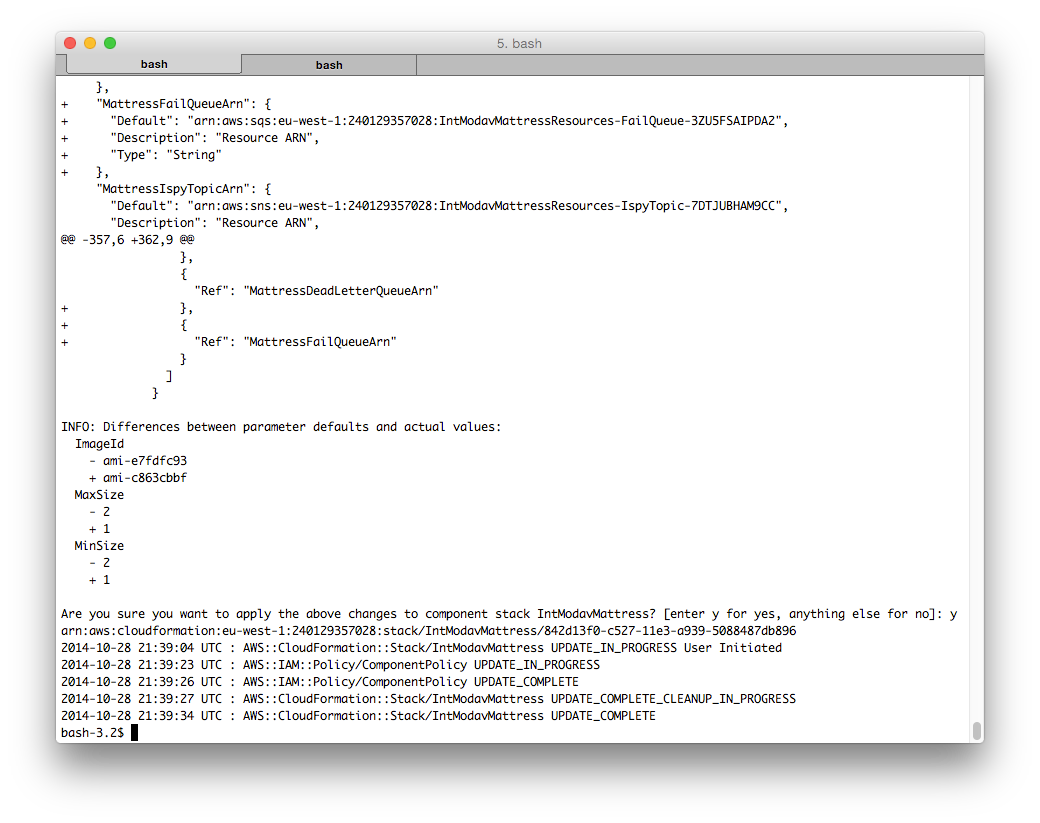
stack-updater polls the stack's status, waiting for it to reach a terminal state (i.e. not “in progress”). The stack events are displayed as they occur.
In this case the stack update completes successfully, and stack-updater's work is done.
In more detail
stack-fetcher is a name given to a collection of scripts, one of which is itself called “stack-fetcher”. The other script that is intended to be manually invoked is “stack-updater”. There are other scripts, but one of the goals of stack-fetcher is to invoke and orchestrate those other scripts so that the user doesn't generally have to think about them.
stack-fetcher
stack-fetcher's job is to generate a set of three outputs:
- current is the existing stack, fetched from CloudFormation
- generated is the stack that you want, generated from your codebase
- next is what you're going to push back to CloudFormation using “stack-updater”
When stack-fetcher runs, next is generated simply as a copy of current — that is, if you don't edit the next file, then you won't push any changes.
To make generated, stack-fetcher runs a series of scripts. Currently, this step is rather BBC-specific: we invoke ./generate-templates with PYTHON_LIB set to point to part of the stack-fetcher codebase; if there's a transform script, then the json is then filtered through this; then there's a cosmos-cloudformation-postproc script which post-processes the json in various ways — primarily, providing defaults for the stack's parameters.
To make current, stack-fetcher needs to know what stack name it should work with — and again, currently calculating this stack name is fairly BBC-specific. Once entered, the stack name is remembered via the ./stack_names.json file, so you don't have to calculate or enter it again. Once the stack name is known, the existing stack template and descriptor are fetched, and saved as current.
After this, stack-fetcher normalises both current and generated. The purpose of the normalisation is partly to make the files more readable, but also to get rid of differences that are meaningless. As well as whitespace reformatting and sorting object keys, the normalisation also includes CloudFormation-specific elements, such as sorting parameters, tags and outputs; removing empty arrays, if that would mean the same thing; and even re-ordering statements within IAM Policies.
next always starts off as a copy of current, so that by default no changes are pushed.
Finally, stack-fetcher compares current and generated and shows a simple summary: they're either the “SAME” or “DIFFERENT” (or, if the stack doesn't exist yet, “NEW”); then shows some help text describing what to do next.
diff/merge
The help text displayed by stack-fetcher suggests using vimdiff to compare and edit the files, but of course you can use whatever tools you wish. The goal of this step is to update next to reflect what you want pushed back into CloudFormation (whilst leaving the current and generated files unchanged).
You may wish to simply review that generated is exactly what you want, then copy generated over next (this is probably what you want, ideally); or, you can cherry-pick, and perform more complex merges.
stack-updater
Once you've updated next to be as desired, you invoke stack-updater, with exactly the same arguments as you did for stack-fetcher.
If there are any differences between the set of parameters declared in the stack template, and the set of parameters passed in the stack descriptor, then stack-updater shows those differences (e.g. “You're passing a parameter called X but it doesn't exist”), automatically applies corrections (e.g. removing the no-longer-existent parameter), then stops, so that you can check its changes before re-running stack-updater.
Assuming the stack already exists, then stack-updater now diffs current against next — that is, it shows you the changes you're about to push. It also displays the differences between the stack's parameter defaults, and the actual parameter values you're passing, so you can check which ones you're overriding. (If the stack doesn't currently exist, then this step is skipped, and the confirmation step up next reminds you that you're about to create the stack).
It then asks for confirmation to proceed, and if you say yes, then the change is pushed using the CloudFormation “update stack” (or “create stack”) API, and then stack-updater polls the stack status, waiting for completion.
Finally there's another BBC-specific step, wherein the stack can be registered in Cosmos, our deployment manager.
Dependencies
stack-fetcher is written in ruby, and uses the aws-sdk gem.
Benefits
By using this tool, we have realised several benefits:
- speed: Using this tool is much quicker than using the other (several) tools that we used before. There are fewer commands to type, with fewer options to remember. And probably most importantly, you never have to leave your terminal.
- consistency: By automating more of the process, and by normalising the output, we now achieve more consistency: by which I mean between developers, between environments, and between components.
- understanding: This tool makes it very obvious what changes you're about to apply to live (or whatever environment you're updating) — no more blind pasting of a load of json and hoping for the best — which means fewer mistakes.
All of which means: this tool has helped us to be more productive.
Next steps
We need to separate out the BBC-specific parts from the rest, so that we can offer this tool out to a wider audience.
I'd like to make the “generation” phase more uniform: run a series of executables (bash, ruby, whatever — the tool should not care), where the first executable receives null input, and each subsequent tool filters the output of the previous one. So for example you might have filters which do: make the basic template; customise it for this environment; fill in parameter defaults.
I don't have any news yet of when this might happen, but I certainly want it to happen. Please drop me a line via a comment or on twitter if you have thoughts on this — I'd love to hear your feedback.